
Python, one of the most popular high-level programming languages, is lauded for its simplicity, readability, and versatility. A critical component that makes Python so powerful is its use of data structures. This chapter will focus on essential data structures: lists, tuples, sets, and dictionaries. We’ll also explore how to work with sequences, specifically through slicing, indexing, and list comprehensions.
List
In Python, a list is one of the most flexible and powerful data types. A list is a collection of items that is ordered and changeable, allowing duplicate members. In Python, lists are written with square brackets [] and the elements are separated by commas.
Each value (also called item or element) in the list has an assigned index value. It is important to note that Python is a zero-indexed programming language, meaning that the first item in the list has an index of 0, the second item has an index of 1, and so on.
A list can contain any Python type. But a list itself is also a Python type. That means a list can contain numbers, strings, other lists, etc.
Let’s look at a detailed example:
# Creating a list
fruits = ['apple', 'banana', 'cherry', 'orange', 'kiwi']
print(fruits)
# Output: ['apple', 'banana', 'cherry', 'orange', 'kiwi']
# Accessing elements of a list using index
print(fruits[0])
# Output: apple
# Changing the value of a specific item in the list using its index
fruits[1] = 'blackberry'
print(fruits)
# Output: ['apple', 'blackberry', 'cherry', 'orange', 'kiwi']
# Adding an item to the end of the list using append()
fruits.append('banana')
print(fruits)
# Output: ['apple', 'blackberry', 'cherry', 'orange', 'kiwi', 'banana']
# Removing an item from the list using remove()
fruits.remove('cherry')
print(fruits)
# Output: ['apple', 'blackberry', 'orange', 'kiwi', 'banana']
# Removing an item from a specific index in the list using pop()
fruits.pop(2)
print(fruits)
# Output: ['apple', 'blackberry', 'kiwi', 'banana']

These are just a few of the operations you can perform on lists. Lists are very powerful and flexible data structures that can be used to store collections of items in Python.
To illustrate the use of lists, let’s take an example from a real-life scenario: managing a library.
Suppose you are a librarian and you want to keep track of the books currently available in the library. In Python, you could represent this collection of books as a list:
# list of books in the library books = ['The Great Gatsby', 'Moby Dick', 'To Kill a Mockingbird', '1984', 'Pride and Prejudice'] print(books) # Output: ['The Great Gatsby', 'Moby Dick', 'To Kill a Mockingbird', '1984', 'Pride and Prejudice']
Next, suppose a new book arrives and you want to add it to your collection:
# a new book arrives new_book = 'War and Peace' books.append(new_book) print(books) # Output: ['The Great Gatsby', 'Moby Dick', 'To Kill a Mockingbird', '1984', 'Pride and Prejudice', 'War and Peace']
Then, let’s say a customer borrows “1984”. You’ll need to remove it from the list:
# a book is borrowed borrowed_book = '1984' books.remove(borrowed_book) print(books) # Output: ['The Great Gatsby', 'Moby Dick', 'To Kill a Mockingbird', 'Pride and Prejudice', 'War and Peace']
Finally, perhaps you want to display only the first three books in the library. You can use slicing for this:
# display the first three books print(books[0:3]) # Output: ['The Great Gatsby', 'Moby Dick', 'To Kill a Mockingbird']
As you can see from this real-life example, Python lists can be instrumental in organizing, storing, and manipulating collections of items, regardless of the context or scale.
Let’s see another real-world example of a List in Python.
For instance, imagine you’re a software engineer working on a spacecraft control system. Part of your job might involve managing a schedule of tasks that the spacecraft has to execute. This could include actions like running system checks, collecting sensor data, orienting solar panels, and sending status reports.
Here’s how you could represent and manipulate this schedule using a Python list:
# List of tasks for the spacecraft to execute
task_schedule = ["System Check", "Sensor Data Collection", "Solar Panel Orientation", "Status Report"]
# Printing the list of tasks
print(task_schedule)
# Output: ['System Check', 'Sensor Data Collection', 'Solar Panel Orientation', 'Status Report']
# Adding a new task to the schedule using append()
task_schedule.append("Star Observation")
print(task_schedule)
# Output: ['System Check', 'Sensor Data Collection', 'Solar Panel Orientation', 'Status Report', 'Star Observation']
# Removing a task from the schedule using remove()
task_schedule.remove("Sensor Data Collection")
print(task_schedule)
# Output: ['System Check', 'Solar Panel Orientation', 'Status Report', 'Star Observation']
# Accessing a task in the schedule by its index
print(task_schedule[1])
# Output: 'Solar Panel Orientation'
# Changing a task in the schedule
task_schedule[2] = "Detailed System Check"
print(task_schedule)
# Output: ['System Check', 'Solar Panel Orientation', 'Detailed System Check', 'Star Observation']

In this example, the list task_schedule is used to keep track of a sequence of tasks. We can easily add or remove tasks, change an existing task, or access a task based on its position in the schedule. This kind of manipulation is common when dealing with ordered collections of items or tasks in software systems.
Tuple
In Python, a tuple is another standard data type that works as a container for other values. The main characteristics of a tuple are:
Ordered: The order in which items are added to a tuple is preserved.
Immutable: Unlike lists, tuples are immutable, which means that after a tuple is created, you cannot add, remove, or modify its elements.
Tuples are defined by enclosing a comma-separated sequence of objects in parentheses (). An important note: defining a tuple with one element requires a trailing comma. For instance, single = (1,) is a tuple, while not_a_tuple = (1) is not a tuple (it’s an integer).
Let’s look at a detailed example:
# Creating a tuple
fruits = ('apple', 'banana', 'cherry', 'orange', 'kiwi')
print(fruits)
# Output: ('apple', 'banana', 'cherry', 'orange', 'kiwi')
# Accessing elements of a tuple using index
print(fruits[0])
# Output: 'apple'
# Trying to change the value of a specific item in the tuple using its index
# This will lead to TypeError because tuples are immutable
# fruits[1] = 'blackberry'
# However, you can find the index of an element
print(fruits.index('cherry'))
# Output: 2
# And you can count the number of occurrences of a specific element
print(fruits.count('apple'))
# Output: 1
# A tuple with a single element needs a comma to differentiate it from a parenthesized expression
single_fruit = ('apple',)
print(single_fruit)
# Output: ('apple',)

These operations demonstrate the basic properties of tuples: ordered and immutable. These properties make tuples useful for grouping related data or when you need an unchangeable list of items.
Tuples in Python can be a helpful data type in real-world situations where you want to group together related data and make sure it cannot be changed due to its immutability property.
Consider a real-life scenario where you are building a system to keep track of student records. In this context, you might have data for each student that includes their student ID number, name, and the course they are enrolled in. This data can be grouped into a tuple, where:
The first element, at index 0, is the student ID (an integer).
The second element, at index 1, is the student’s name (a string).
The third element, at index 2, is the student’s course (a string).
In Python, you would define this tuple as follows:
# Creating a tuple for a student student = (12345, 'John Doe', 'Computer Science') print(student) # Output: (12345, 'John Doe', 'Computer Science')

Now, suppose you have a list of students, each represented by a tuple as described. You can access the information for each student using the appropriate index:
# List of students
students = [
(12345, 'John Doe', 'Computer Science'),
(67890, 'Jane Smith', 'Mechanical Engineering'),
(11223, 'Emily Johnson', 'Mathematics'),
]
# Accessing data of the first student
first_student = students[0]
print(first_student)
# Output: (12345, 'John Doe', 'Computer Science')
# Accessing the name of the first student
first_student_name = first_student[1]
print(first_student_name)
# Output: 'John Doe'

In this example, tuples are used to ensure that the data for each student stays together as a single unit. The immutability of tuples provides a guarantee that the data won’t be accidentally changed later in the program. This shows how tuples can effectively be used in a real-life context.
In the context of aerospace software, tuples can be quite useful. Let’s consider an example related to a satellite control system. Suppose you’re managing a constellation of satellites, each of which can be uniquely identified by a set of attributes like its name, model, and launch date. Since these attributes will not change once the satellite is launched, they can be stored in a tuple.
Here’s how you could represent and manage this data using Python tuples:
# Defining a tuple for a satellite
satellite = ("Hubble Space Telescope", "HS-601", "1990-04-24")
# Accessing data in a tuple
print(f"Satellite Name: {satellite[0]}")
# Output: Satellite Name: Hubble Space Telescope
print(f"Satellite Model: {satellite[1]}")
# Output: Satellite Model: HS-601
print(f"Launch Date: {satellite[2]}")
# Output: Launch Date: 1990-04-24
# Trying to change an item in the tuple (this should produce an error because tuples are immutable)
satellite[1] = "HS-602"
# Output: TypeError: 'tuple' object does not support item assignment
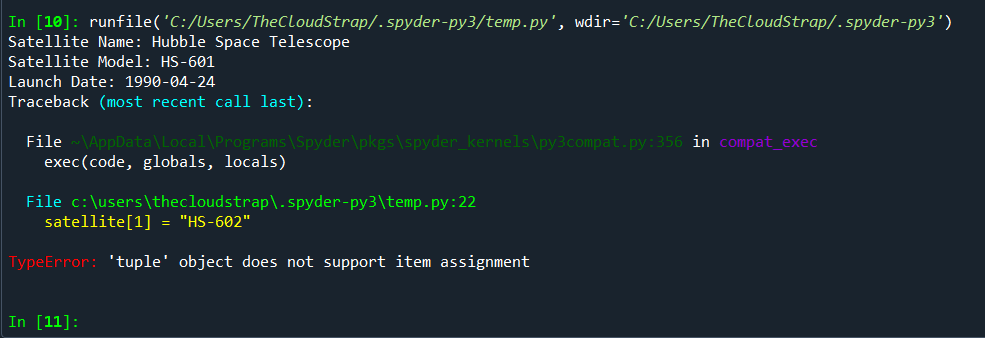
In this example, a tuple provides an efficient way to group related data together. It ensures the integrity of the data because it’s immutable: once the tuple is created, its content cannot be changed. This is particularly important in the field of aerospace, where stability and predictability are crucial.
Sets
A set in Python is an unordered collection of unique elements. The characteristics of a set include:
- Unordered: The elements in a set are stored in no particular order.
- Unindexed: Elements in a set cannot be accessed using indexes.
- Mutable: However, you can add or remove items from a set.
- No duplicates: A set cannot contain duplicate elements.
- Sets are defined by enclosing a comma-separated sequence of objects in curly braces {}. Python also provides a built-in set() constructor to create a set.
Here is a detailed example of a set in Python:
# Creating a set
fruits = {'apple', 'banana', 'cherry', 'orange', 'kiwi'}
print(fruits)
# Output: {'apple', 'cherry', 'banana', 'kiwi', 'orange'}
# Adding an element to a set using add()
fruits.add('mango')
print(fruits)
# Output: {'apple', 'cherry', 'banana', 'kiwi', 'orange', 'mango'}
# Adding multiple elements to a set using update()
fruits.update(['pineapple', 'guava'])
print(fruits)
# Output: {'pineapple', 'guava', 'kiwi', 'mango', 'cherry', 'banana', 'apple', 'orange'}
# Removing an element from a set using remove()
fruits.remove('banana')
print(fruits)
# Output: {'pineapple', 'guava', 'kiwi', 'mango', 'cherry', 'apple', 'orange'}
# Checking if an element exists in a set
print('apple' in fruits)
# Output: True
# Trying to create a set with duplicate elements
nums = {1, 2, 2, 3, 4, 4, 4, 5}
print(nums)
# Output: {1, 2, 3, 4, 5} - No duplicate elements in the output

As shown in the example, even if you try to add duplicate elements to a set, Python will automatically remove the duplicates and only unique elements will be preserved. Sets are useful when you want to keep track of a collection of elements, but don’t care about their order, don’t need to access them by index, and want to ensure that no duplicates are present.
Sets in Python can be a very useful data type in a number of real-world applications, particularly in situations where you need to manage collections of items, and it’s important to avoid duplicates or to perform operations like set union or intersection.
Let’s consider a real-life scenario where you are a school administrator. You have two lists of students: one list for students enrolled in a Math class and another for students in an English class. You want to find out which students are taking both classes and which students are taking at least one class.
# Set of students in the Math class
math_students = {"John", "Jacob", "Julie", "Luke"}
# Set of students in the English class
english_students = {"Julie", "Luke", "Sam", "Emma"}
# Find students who are in both classes (Intersection of two sets)
students_in_both = math_students.intersection(english_students)
print(students_in_both)
# Output: {"Julie", "Luke"}
# Find students who are taking at least one class (Union of two sets)
students_in_either = math_students.union(english_students)
print(students_in_either)
# Output: {"John", "Jacob", "Julie", "Luke", "Sam", "Emma"}

In this example, the use of sets made it easy to perform operations like finding the common students (intersection) and combining the students (union). The guarantee that a set does not contain duplicates can also be very useful in many real-world scenarios. Remember, though, that sets are unordered and unindexed, meaning you cannot access or manipulate elements of a set using index positions.
For a real-world example of aerospace software, let’s consider the case of an air traffic control system. One of the system’s responsibilities could be to keep track of unique aircraft currently in the airspace it’s monitoring. Because sets automatically remove duplicates, they’re a great choice for this task:
# Set of unique aircraft currently in airspace
aircraft_in_airspace = {'A320', 'B737', 'A380', 'B787', 'A350', 'B777'}
# Print the set of aircraft
print(aircraft_in_airspace)
# Output: {'A380', 'A350', 'B787', 'B777', 'A320', 'B737'}
# Trying to add a duplicate aircraft - 'A380'
aircraft_in_airspace.add('A380')
print(aircraft_in_airspace)
# Output: {'A380', 'A350', 'B787', 'B777', 'A320', 'B737'} - 'A380' was not added again
# Adding a new aircraft - 'B747'
aircraft_in_airspace.add('B747')
print(aircraft_in_airspace)
# Output: {'B747', 'A380', 'A350', 'B787', 'B777', 'A320', 'B737'} - 'B747' has been added
# Checking if an aircraft is in the airspace
print('B737' in aircraft_in_airspace)
# Output: True
# Removing an aircraft
aircraft_in_airspace.remove('B787')
print(aircraft_in_airspace)
# Output: {'B747', 'A380', 'A350', 'B777', 'A320', 'B737'} - 'B787' has been removed

As shown in this example, a set in Python provides a way to store unique items efficiently. This is particularly useful when dealing with a collection of items where duplicates are not allowed or meaningful, like tracking distinct objects in airspace.
Dictionaries
A dictionary in Python is a mutable and unordered collection of key-value pairs. Here are the main characteristics of dictionaries:
Unordered: The elements in a dictionary are stored in no particular order.
Keys and Values: Elements are stored as key-value pairs. Each key-value pair maps the key to its associated value.
Accessed by Key: Values in a dictionary can be accessed using their key, not their position.
Mutable: Dictionaries can be changed; you can add, remove, and update key-value pairs.
No Duplicate Keys: A dictionary cannot have two identical keys.
Dictionaries are defined by enclosing a comma-separated list of key-value pairs in curly braces {}. A colon : separates each key from its associated value. Here is a detailed example:
# Creating a dictionary
fruits = {'apple': 1, 'banana': 2, 'cherry': 3}
print(fruits)
# Output: {'apple': 1, 'banana': 2, 'cherry': 3}
# Accessing elements of a dictionary using keys
print(fruits['apple'])
# Output: 1
# Changing the value of a specific item in the dictionary using its key
fruits['banana'] = 4
print(fruits)
# Output: {'apple': 1, 'banana': 4, 'cherry': 3}
# Adding a new key-value pair to the dictionary
fruits['orange'] = 5
print(fruits)
# Output: {'apple': 1, 'banana': 4, 'cherry': 3, 'orange': 5}
# Removing a key-value pair from the dictionary using del
del fruits['cherry']
print(fruits)
# Output: {'apple': 1, 'banana': 4, 'orange': 5}
# Checking if a key is in the dictionary
print('apple' in fruits)
# Output: True

As shown in this example, dictionaries in Python are very versatile and useful when you need to associate keys with values, retrieve values based on their keys, and modify values associated with specific keys.
Dictionaries in Python are particularly useful in real-world applications where data is structured and can be mapped directly to unique identifiers – the keys.
Consider a real-world scenario of managing a phone directory. Each person in the directory has a name and an associated phone number. In this case, you can use the person’s name as a key and the phone number as the value.
Here is how you would implement this in Python:
# Creating a phone directory as a dictionary
phone_directory = {
'John Doe': '555-1234',
'Jane Smith': '555-5678',
'Emily Davis': '555-8765'
}
print(phone_directory)
# Output: {'John Doe': '555-1234', 'Jane Smith': '555-5678', 'Emily Davis': '555-8765'}
# Accessing John Doe's phone number
print(phone_directory['John Doe'])
# Output: '555-1234'
# Updating Jane Smith's phone number
phone_directory['Jane Smith'] = '555-4321'
print(phone_directory)
# Output: {'John Doe': '555-1234', 'Jane Smith': '555-4321', 'Emily Davis': '555-8765'}
# Adding a new entry to the phone directory
phone_directory['Tom Johnson'] = '555-9876'
print(phone_directory)
# Output: {'John Doe': '555-1234', 'Jane Smith': '555-4321', 'Emily Davis': '555-8765', 'Tom Johnson': '555-9876'}
# Deleting an entry from the phone directory
del phone_directory['Emily Davis']
print(phone_directory)
# Output: {'John Doe': '555-1234', 'Jane Smith': '555-4321', 'Tom Johnson': '555-9876'}

In this real-life example, the dictionary allowed us to represent each person’s phone number in a structured way, with the person’s name serving as a unique identifier for accessing their phone number. This is a common use case for dictionaries in Python – to store and manage data that can be represented as unique pairs of keys and values.
Let’s see another real-world example. Imagine you’re a software engineer tasked with tracking test results for a number of critical software modules in an aerospace system. Each software module can have multiple tests associated with it, and each test will have a status, such as ‘Pass’, ‘Fail’, or ‘Not Run’. This scenario is a perfect use case for a dictionary.
Here’s how you could represent and manage this data using a Python dictionary:
# Define a dictionary to store test results
test_results = {
'Navigation': {'Test 1': 'Pass', 'Test 2': 'Fail', 'Test 3': 'Pass'},
'Communication': {'Test 1': 'Pass', 'Test 2': 'Pass', 'Test 3': 'Not Run'},
'Power': {'Test 1': 'Not Run', 'Test 2': 'Not Run', 'Test 3': 'Not Run'}
}
# Accessing the test results for the Navigation module
print(test_results['Navigation'])
# Output: {'Test 1': 'Pass', 'Test 2': 'Fail', 'Test 3': 'Pass'}
# Accessing a specific test result
print(test_results['Communication']['Test 2'])
# Output: 'Pass'
# Updating a test result
test_results['Power']['Test 1'] = 'Pass'
print(test_results['Power'])
# Output: {'Test 1': 'Pass', 'Test 2': 'Not Run', 'Test 3': 'Not Run'}
# Adding a new test result
test_results['Navigation']['Test 4'] = 'Fail'
print(test_results['Navigation'])
# Output: {'Test 1': 'Pass', 'Test 2': 'Fail', 'Test 3': 'Pass', 'Test 4': 'Fail'}

In this example, a dictionary provides an efficient way to track test results across multiple software modules, each having multiple associated tests. Because each test is linked to its status through a key-value pair, it’s easy to update statuses, add new tests, or look up the results for a specific test. This makes dictionaries a highly useful tool for managing complex, structured data in software testing.
Working with sequences (slicing, indexing)
In Python, sequences are a type of data structure that can hold zero or more items, which are stored in a specific order. Strings, lists, and tuples are examples of sequences in Python.
One key feature of sequences is that you can access their elements through indexing and slicing:
Indexing means accessing an element of a sequence using its position. In Python, indices start from 0. So the first element of a sequence is at index 0, the second is at index 1, and so on. Python also supports negative indexing, where -1 refers to the last item, -2 refers to the second last item, and so forth.
Slicing means accessing a range of items in a sequence. It is performed by defining the index values of the first item and the last item from the parent sequence that is required in the new sequence. Note that the last index is exclusive, which means the item at that index will not be included in the slice.
Let’s go through some detailed examples of indexing and slicing using lists and strings.
Lists
# Creating a list my_list = ['apple', 'banana', 'cherry', 'orange', 'kiwi', 'melon'] # Indexing: Accessing the first item print(my_list[0]) # Output: 'apple' # Indexing: Accessing the last item with negative indexing print(my_list[-1]) # Output: 'melon' # Slicing: Getting the first three items print(my_list[:3]) # Output: ['apple', 'banana', 'cherry'] # Slicing: Getting the items from index 2 to 4 print(my_list[2:5]) # Output: ['cherry', 'orange', 'kiwi'] # Slicing: Getting the last two items print(my_list[-2:]) # Output: ['kiwi', 'melon']

Strings
# Creating a string my_str = 'Hello, World!' # Indexing: Accessing the first character print(my_str[0]) # Output: 'H' # Indexing: Accessing the last character with negative indexing print(my_str[-1]) # Output: '!' # Slicing: Getting the first five characters print(my_str[:5]) # Output: 'Hello' # Slicing: Getting the characters from index 7 to 11 print(my_str[7:12]) # Output: 'World' # Slicing: Getting the last six characters print(my_str[-6:]) # Output: 'World!'

Remember, indexing and slicing can be used with any sequence type in Python. They are a powerful tool that allows you to access data in versatile ways.
Examples
Working with sequences is fundamental in a broad range of applications, including aerospace software systems. Python’s ability to easily manipulate lists (a kind of sequence) is often utilized in processing data, performing computations, and managing system states. Here are some real-life examples:
Managing Aircraft Fleet
In this scenario, let’s say you’re managing a fleet of aircraft, each having a unique identifier (tail number). This can be represented as a list. If you need to access specific aircraft for maintenance updates or status checks, you would use indexing.
# List of aircraft in the fleet fleet = ['N123AA', 'N456BB', 'N789CC', 'N321DD', 'N654EE'] # Accessing an aircraft print(fleet[2]) # Output: 'N789CC'

Flight Data Processing
Python is frequently used to process and analyze flight data. For instance, a software system might ingest a sequence of altitude data recorded during a flight. If you want to analyze a specific segment of the flight, you would use slicing.
# Hypothetical altitude data (in feet) altitude_data = [10000, 15000, 20000, 25000, 30000, 35000, 40000, 35000, 30000, 25000, 20000, 15000, 10000] # Analyzing climb phase (assuming the aircraft started climbing at index 0 and reached cruise altitude at index 6) climb_data = altitude_data[:7] print(climb_data) # Output: [10000, 15000, 20000, 25000, 30000, 35000, 40000]

Satellite Position Tracking
If you’re tracking a satellite’s position, you might have a list of positions recorded as (x, y, z) tuples representing coordinates in 3D space. To access a specific coordinate, you would use indexing.
# Satellite position data [(x1, y1, z1), (x2, y2, z2), ..., (xn, yn, zn)] positions = [(1, 2, 3), (4, 5, 6), (7, 8, 9), (10, 11, 12), (13, 14, 15)] # Accessing a specific position print(positions[3]) # Output: (10, 11, 12)

These examples illustrate how fundamental sequence operations, such as indexing and slicing, are used in aerospace software systems. As Python continues to grow in popularity in scientific and engineering fields, these operations become even more essential.
List Comprehensions
List comprehensions are a unique feature of Python that allows you to create lists in a very concise and elegant way. This can be particularly valuable when you need to play out some procedure on every component of a rundown, or when you need to make a rundown in view of some condition.
Here is the general format of a list comprehension:
new_list = [expression for item in iterable]
This creates a new list by performing an operation defined by expression on each item in the iterable.
Let’s consider a simple example where we want to create a new list containing the squares of all numbers in an existing list:
# Existing list of numbers numbers = [1, 2, 3, 4, 5] # Using a list comprehension to create a new list of squares squares = [n**2 for n in numbers] print(squares) # Output: [1, 4, 9, 16, 25]

In this example, n**2 is the expression that’s being performed on each item in the numbers list.
You can also use list comprehensions with a condition. For instance, if you only wanted to square the numbers that are greater than 2, you could do:
# Existing list of numbers numbers = [1, 2, 3, 4, 5] # Using a list comprehension to create a new list of squares for numbers greater than 2 squares = [n**2 for n in numbers if n > 2] print(squares) # Output: [9, 16, 25]

In this example, if n > 2 is the condition that each item in the list must meet to be included in the new list. If an item doesn’t meet this condition, it’s not included in the new list.
Let’s see another example.
Let’s imagine you’re working on testing the software of a new electric vehicle. You have a list of recorded data on battery temperature from multiple test runs. You want to analyze runs where the battery temperature exceeded a certain limit (say, 60 degrees Celsius).
Here’s how you could use list comprehension to process this:
# List of battery temperatures from multiple test runs (in degrees Celsius) battery_temps = [55, 58, 60, 63, 56, 62, 61, 57, 59, 64] # Using list comprehension to get test runs where battery temperature exceeded 60 degrees high_temp_runs = [temp for temp in battery_temps if temp > 60] print(high_temp_runs) # Output: [63, 62, 61, 64]

In this case, the list comprehension [temp for temp in battery_temps if temp > 60] creates a new list high_temp_runs containing only those temperatures that are greater than 60. This is an easy and efficient way to filter out the relevant data from the test results.
In another scenario, you might have a list of test run identifiers (IDs) for the test runs that passed, and another list with all test run IDs. You could use list comprehension to determine which tests failed:
# All test run IDs all_runs = ['Run1', 'Run2', 'Run3', 'Run4', 'Run5', 'Run6', 'Run7', 'Run8', 'Run9', 'Run10'] # Passed test run IDs passed_runs = ['Run1', 'Run2', 'Run3', 'Run5', 'Run8', 'Run10'] # Using list comprehension to find failed test run IDs failed_runs = [run for run in all_runs if run not in passed_runs] print(failed_runs) # Output: ['Run4', 'Run6', 'Run7', 'Run9']

In this case, the list comprehension [run for run in all_runs if run not in passed_runs] creates a new list of failed_runs containing the IDs of the test runs that didn’t pass.
These examples demonstrate how list comprehensions can help efficiently process and analyze test data in the field of automotive software testing.

This post was published by Admin.
Email: admin@TheCloudStrap.Com